
Trees… and Bots: Conversational AI with Trees?
Sample application:
Conversational survey that asks users about urban green spaces within cities in terms of potential benefits. This approach is using a large language model, in this case, it’s davinici-text from OpenAI, along with GCP’s text to speech and speech to text API’s. This approach is significantly better than using a virtual assistant. Especially since people are interacting with the model, the model has the ability to train on previous answers and suggest some answers. Running this is also less computationally intensive due to the cloud based API’s, rather than a system installed on the raspberry pi that process some elements and communicates back and forth with the cloud.
[To be added, hopefully soonish: the model running on an RPi, where the RPi is running on a tree connected to tree sensors.]
The other approach is using a virtual assistant, e.g. I used an Alexa SDK and installed on a raspberry pi. The system works in a very similar way to interacting with Alexa, Siri, google assistant. This approach is different, since I hard coded intents and answers about the project to train it to respond in the way we want.
[demo about this to be added, hopefully soonish…]
Alexa.. For Trees: Would Conversational AI and bots make talking to tree more natural?
Natural assets’ benefits include social values, inherently associated with better physical and mental health. Active interactions between people and natural assets has been constrained to individuals texting messages back and forth with HelloLampPost [HelloUBC] servers through the campus’s inanimate objects, such as parking meters and lamp posts. Our approach introduces a pseudo-natural approach where introducing conversational AI to trees may allow people to feel more welcome and included within green spaces. People would have the ability to ask trees questions, and the trees would vocally respond back about the project itself, their own distress levels, or any random topics.
Conversational AI is a virtual assistant, connected to a cloud computing server, that responds with commands and/or phrases upon specific engagements from users. Examples include Google’s Home Assistant, where a user prompts the device to wake up using a very specific phrase, i.e. keyword. When the device enters the listening phase, the user mentions a phrase or a command, prompting the device to send to the cloud server to search for answers pertaining to the phrase, or issue pre-programmed commands to control network-connected devices. Searchable prompts include questions that require the device to provide answers for, whether pre-programmed answers or answers based on internet searches.
On the RPi, we ported an (Amazon) Alexa-based system, using the Alexa-SDK, utilizing Alexa’s keyword spotting, speech/language recognition, text-to-speech, and custom programmed intents/ answers, e.g. prompting Alexa to respond about the UBC-Rogers’ project with very specific answers we upload.

MCUs Are More Powerful and Cheaper Now.
Porting a conversational AI on a microcontroller ( ESP32 fitted with a Low Power Wide Area (LPWA) Wireless module) for communications through a cellular network.
Example interaction:
- User: Hi Tree!
- Tree: Hello there! It’s sunny today!
- User: What’s this project about?
- Tree: The University of British Columbia is home of approximately 8,000 trees planted and over 10,000 native trees in natural settings. Through this project, we’re trying to understand how trees interact with their environment.
On the other hand, the conversational AI ported onto the ESP32 requires manual training for keyword spotting. For this, we used Mozilla’s pre-trained CommonVoice. We used a microphone module to capture audio signals, which are then uploaded to Facebook’s Wit.ai’s audio intent recognition. The device uses intents to understand which command to issue.
This process is more cumbersome, as latencies from audio processing, and recognition are inversely correlated with the processing power of the low-power device. Higher accuracy in audio processing, e.g. noise filtering, requires more time and power, thus, increasing the period in which the device responds to each command. Alternatively, reducing audio processing accuracy, in favour of faster responses, reduces the probability of accurate audio recognition, leading to higher probabilities of the server not properly recognizing intent and providing wrong or an unknown response.
Finding the ideal combination between latency and processing power allows us to better program the system in anticipation of solutions, where latency and accurate responses are instrumental, such as applications dedicated for sentiment-focused mental health applications in green spaces.
A lot more testing, i.e. 5G latency compatibility and intent, is required before testing on the field starts.

Integrations of several sensing systems [different MCUs/SBCs] into one platform
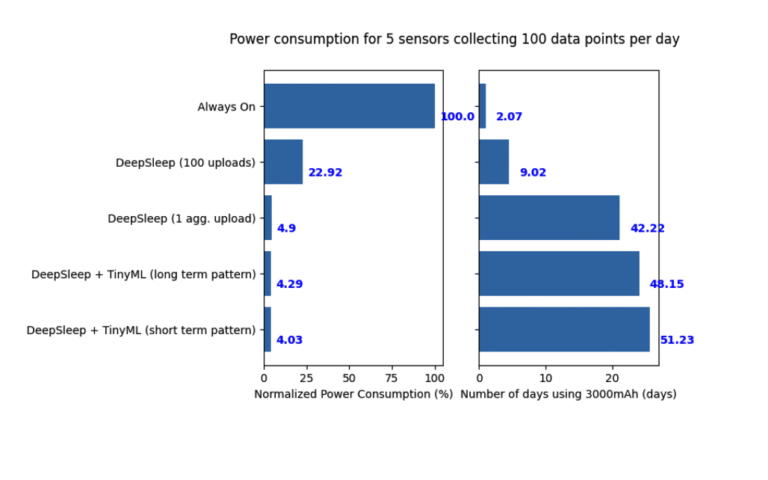
This is a cool graph about power consumption using different software and hardware based optimizations.
I love talking about this board:
The ESP32 Lilygo sim7000g boards are also fitted with a Global Position Sensor (GPS) sensor, solar power input, sim card module, SD card module, and functionality for location, navigation, tracking, mapping and timing applications purposes. The add-ons provide hardware power optimization options, whether in terms of additional power supply to recharge the battery or easier aggregation for data on-board. In addition, software power optimizations can be used to substantially reduce power consumption, such as deep sleep capabilities of the on-board ESP-32 module. The board was chosen due to the software-based power efficiency compatibility.
Software-based power efficiency includes aggregating sensor readings/data before the data is uploaded. The telemetry data is sent in packets, rather than individual messages. In addition, the board allows for automated powering (deepsleep). DeepSleep features allow for the board to turn itself on and off periodically, post data upload. This allows the board to significantly reduce the amount of power required to operate, in terms of on-board modular consumption, sensor operations, as well as the connectivity aspect of identifying suitable cellular connections and data communication. Reduced power consumption maximizes battery power, thus, allowing the devices to stay operational in the field for extended periods of time.
Added benefits:
Aggregating data on-board, with automatic board shutdown, significantly reduces energy consumption, increasing battery cycle by around 79% relative to data being uploaded periodically throughout the day. Telemetry and preprocessed data are uploaded and stored in Azure, InfluxDB through the cellular network and over wifi (figure below). Parameters such as sensor reliability and power consumption in the long term are being evaluated for the feasibility of large scale implementation and will be discussed in more detail in a separate study.
About the microphone:
An I2S-ready microphone is arguably better to connect to an MCU that doesn’t have a sound card.
References:
1. Hello UBC. https://ubc.hlp.city/
