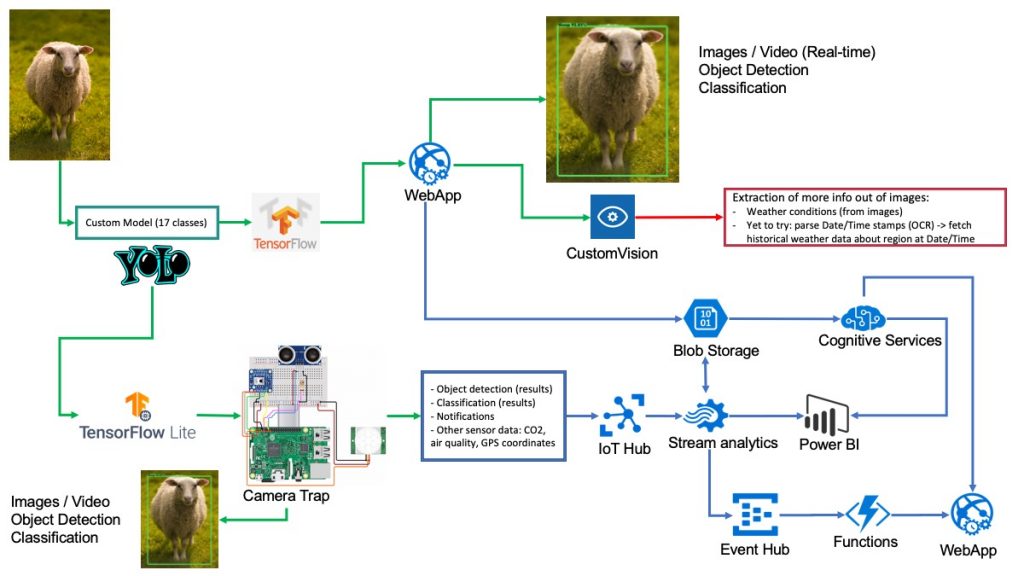
The goal of this project is to highlight how effective Edge AI can be in eliminating/filtering out a significant number of inter-steps between data collection and obtaining classification and detection results, potentially along with other data/features that need to be collected or extracted.
The hope is to utilize such technology to:
Upgrade the current camera traps a bit to help detect and monitor animals faster
Instantaneously detect poachers and notify authorities
Reduce the amount of unnecessarily collected data (and associated cloud/storage costs)
So much more potential for additional studies…
More info:
On a typical camera trap, when embedded sensors detect an activity, the camera collects videos and screenshots to monitor the activity. All the data is saved on the camera/SD card, which is periodically administered by researchers. Afterwards, researchers spend a significant amount of time to manually/ semi-automatically go through the data to detect and classify what’s in the footage.
The idea here is to build a camera trap setup that automates a significant portion of the manual steps. A relatively cheap microcontroller/microcomputer, such as the RPi can be used to build a custom setup. The RPi would connect to a couple of sensors, kinda like an actual/commercial camera trap. The difference here, however, is that we’d upload a custom object detection/classification model. Depending on what researchers want, the RPi can also be connected to a cloud solution for more interesting integration options.
Object Detection and Classification
Model:
Depending on the nature of the project, the custom object detection and classification model would vary. For example, camera traps that are meant to detect a certain species would be slightly different than the ones meant for general observations.
For this project, the model was trained to detect 17 classes, which are all the classes of animals that I was able to manually detect in the MegaDetector demo video.
The classes are Armadillo, Bear, Bird, Bull, [Car], Cat, Cattle, Deer, Dog, Fox, Monkey, [Person], Pig, Raccoon, Sheep, Tiger, and [Truck]. I also added a few classes in [brackets], just in case someone would find the model useful as is. Cars and trucks are typically good indictors of nearby poachers.
YoloV4
YoloV4 to TFLite
What are we classifying?
Using images from Google’s Open Images Dataset V6, I created a model using Yolov4 (AlexeyAB’s darknet). The model is trained for object detection and classification. Then, I tested the model after light training on some test images and the MegaDetector demo video. To run on the RPi, I converted the Yolov4 model to TFLite, using this awesome repo.
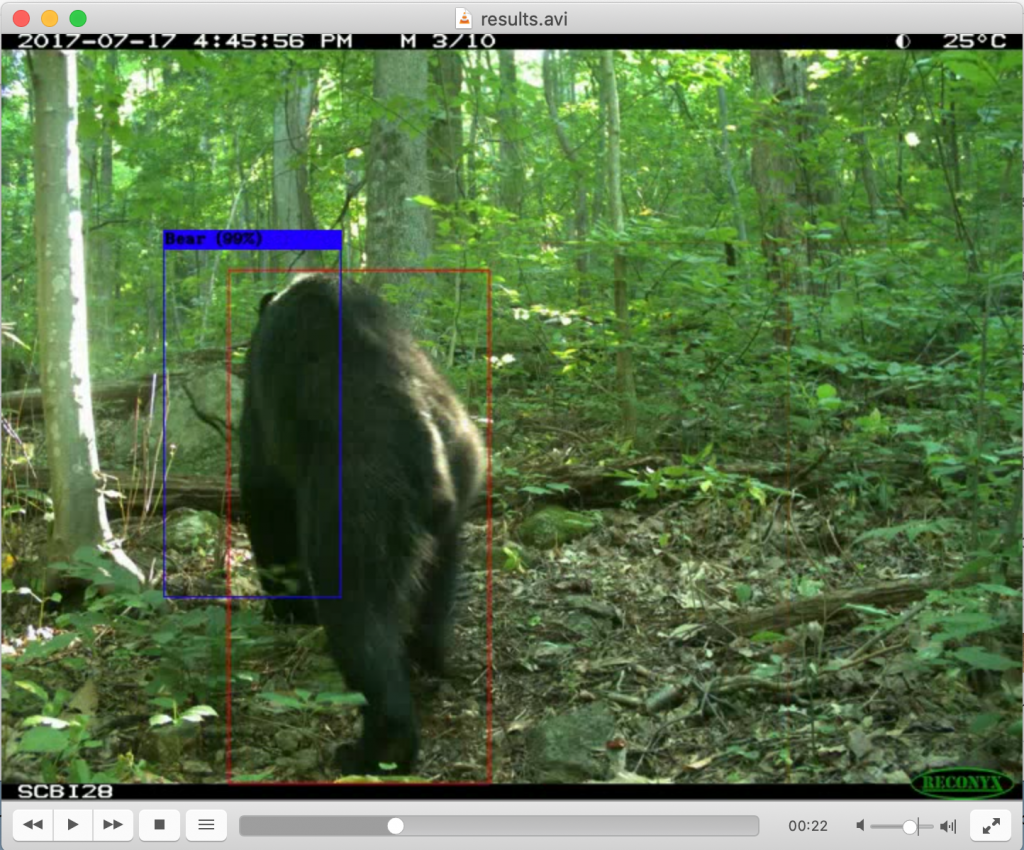
Testing the model on the MegaDetector demo video:
Running the model on the MegaDetector demo video provides reasonably ok results. The detection processing time for the input video is less than 2 minutes.
Some examples of bad detection/classification :
Model needs more training.
Demo
Is it possible to extract more information from images?
Detecting weather conditions from images?
I was wondering if it’s possible to extract more information from images, such as weather conditions.
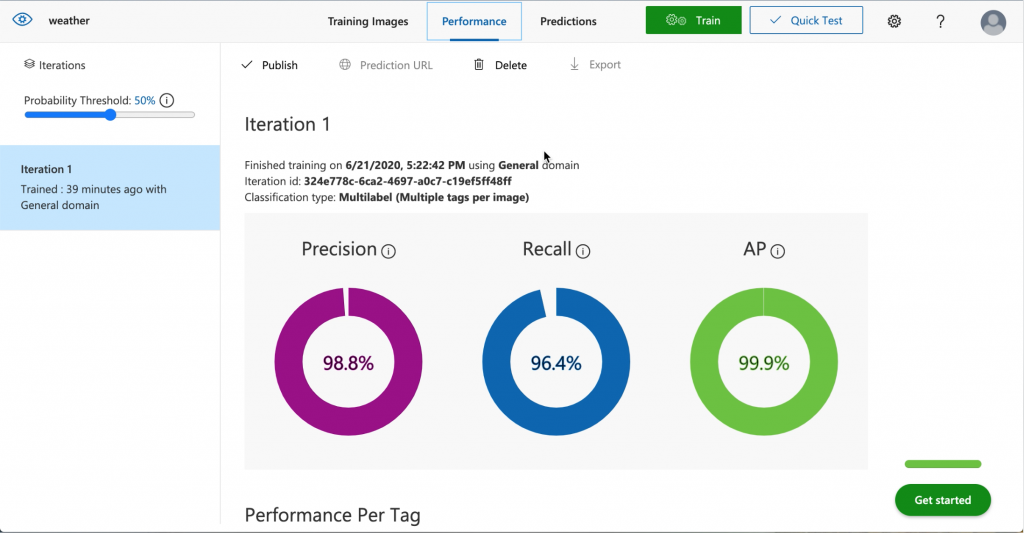
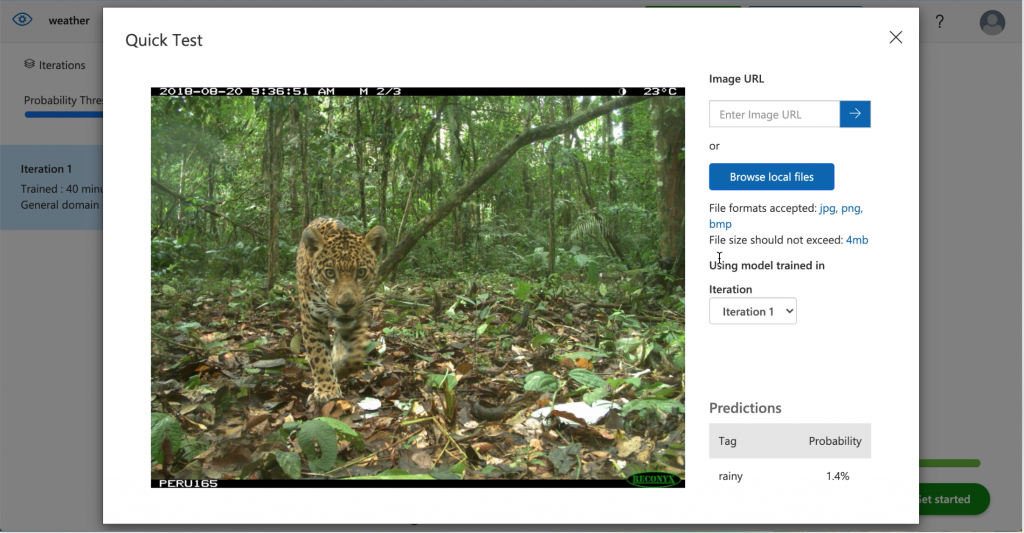
My hand-waving approach was to use Custom Vision to train weather data. I stumbled upon a Multi-class Weather Dataset for Image Classification, which contains 4 classes of weather conditions. So, I used the dataset for training.
Despite the model’s high precision and recall, the accuracy of the classifications is really low.
Next Steps
OCR and Sensors
Another hand-waving approach to extract weather data from camera-trap images (haven’t implemented this yet):
It seems that some images display temperature data in each image. Another approach is to extract temperature information as well as time/date stamps from images (OCR). Then use historical weather datasets (such as openweather API) to fetch other weather features such as humidity, wind direction/speed, weather conditions (rainy, cloudy, partially sunny, sunny), etc..
As mentioned earlier, the main reason to convert the Yolov4 model to a TensorFlow Lite model is for it to run on the raspberry pi. That is, when an image/video is taken, object detection and classification happens on the device itself, where the results can be either uploaded directly to the internet or saved on an SD card. In this approach, only significant data is saved, uploaded, and stored, thus, saving researchers substantial amounts of time as well as significantly reducing cloud/storage services costs.
As the weather information is relatively more challenging to extract directly from images and videos, integrating relatively cheap sensors may provide a more custom overview of the ecosystem. For example, it is possible to add sensors to collect data about emissions such as COx, NOx, NH3, and VOCs as well as air quality. This would also allow for more customizability when it comes to choosing a camera that may be a better fit for custom applications, as well as detection sensors (in this example, pyroelectric/ infrared sensor in addition to an ultrasonic sensor).
Microsoft AI for Earth
More similar projects?
Check out amazing researchers’ projects from around the world!!